Introduction to Browser Network Tab for Web Scraping with Python
Web scraping is an essential tool for extracting data from websites, enabling you to gather valuable information efficiently. In this article, we’ll explore how to use browser network tab for web scraping with python. At the end of this article we will be able to uncover and utilize API requests for web scraping. Using the example of scraping rpilocator.com, we’ll provide a detailed step-by-step guide, including code snippets and best practices.
Why Use the Browser Network Tab for Web Scraping?
The browser’s network tab is a powerful feature for web scraping. It allows you to inspect all HTTP requests made by a webpage, providing insights into the underlying data exchange between the client and server. Here’s why it’s useful:
- API Discovery Made Easy: Many websites use APIs to fetch data dynamically. The network tab helps you identify these API endpoints.
- Accessing Clean and Efficient Data: Accessing API responses directly is faster and cleaner compared to parsing HTML.
- Understanding Cookies and Headers: You can retrieve necessary headers, tokens, or cookies required to make authenticated API requests.
- Debugging and Troubleshooting Web Scraping: It helps understand how a website functions and troubleshoot scraping issues.
Prerequisites for Web Scraping with Python
Before proceeding, ensure you have the following in place:
- Basic knowledge of Python programming.
- A code editor and Python installed on your system.
- The ability to install Python dependencies.
Installation of Dependencies for Web Scraping
To follow along with the provided Python script, install these libraries:
- requests: For making HTTP requests.
pip install requests
Understanding the Browser’s Network Tab
Accessing the Network Tab in Chrome, Firefox, and Edge
The network tab is part of the developer tools in your browser. Here’s how to access it:
- Chrome: Right-click anywhere on the page and select “Inspect” or press
Ctrl+Shift+I(Windows/Linux) orCmd+Option+I(Mac). - Firefox: Right-click and select “Inspect Element” or press
Ctrl+Shift+I(Windows/Linux) orCmd+Option+I(Mac). - Edge: Access it similarly to Chrome.
Navigate to the “Network” tab to see all requests made by the website.
Using the Network Tab for Web Scraping
Here’s what you can do using the network tab:
- Identify the exact request fetching the data you want to scrape.
- Examine headers, parameters, and payloads required for API calls.
- Test API endpoints by copying requests as cURL commands.
- Understand the website’s behavior and spot rate-limiting mechanisms.
How to Identify API Requests for Web Scraping
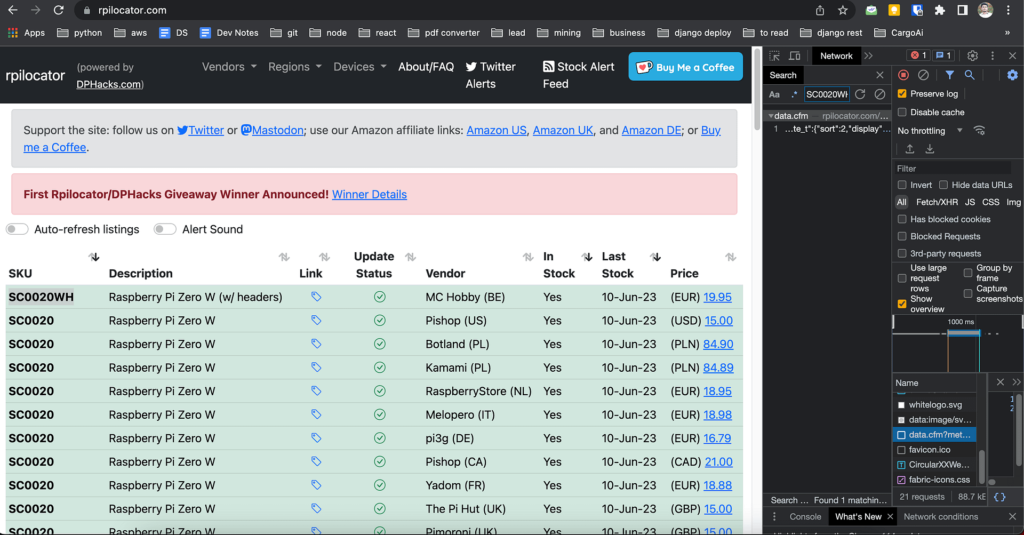
For our example, we’ll scrape data from rpilocator.com, a site that lists Raspberry Pi stock availability. Follow these steps:
- Open the browser’s network tab and navigate to rpilocator.com.
- Refresh the page to load all network requests.
- Search for the request fetching stock data. Use keywords like “SC0020WH” in the search bar.
- Right-click the relevant request and select “Copy as cURL.”
- If needed we can add any available filter before getting the cURL request.

Step-by-Step Guide to Web Scraping with Python Using Browser’s Network Tab
Let’s dive into the Python script and understand how it was developed step-by-step from the cURL request. The script retrieves stock availability data from RPILocator and filters results to display only the desired products that are in stock.
Step 1: Copying Original API Requests in cURL
After identifying the API request using the browser’s network tab, I copied the cURL command for the request:
curl 'https://rpilocator.com/data.cfm?method=getProductTable&cat=PI5&_=1732192856615' \
-H 'accept: application/json, text/javascript, */*; q=0.01' \
-H 'accept-language: en-US,en;q=0.9' \
-H 'cookie: cfid=8be7ee9e-4744-4e3f-9c02-b750fa30154f; cftoken=0; RPILOCATOR=0; CFID=8be7ee9e-4744-4e3f-9c02-b750fa30154f; CFTOKEN=0' \
-H 'dnt: 1' \
-H 'priority: u=1, i' \
-H 'referer: https://rpilocator.com/?cat=PI5' \
-H 'sec-ch-ua: "Google Chrome";v="131", "Chromium";v="131", "Not_A Brand";v="24"' \
-H 'sec-ch-ua-mobile: ?0' \
-H 'sec-ch-ua-platform: "macOS"' \
-H 'sec-fetch-dest: empty' \
-H 'sec-fetch-mode: cors' \
-H 'sec-fetch-site: same-origin' \
-H 'user-agent: Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/131.0.0.0 Safari/537.36' \
-H 'x-requested-with: XMLHttpRequest'
Step 2: Converting the cURL Request to Python
To convert the cURL command into Python code, use a tool like curlconverter.com. Paste the copied cURL command and retrieve the equivalent Python code.

Here’s the initial output after converting the cURL request to Python:
import requests
cookies = {
'cfid': '8be7ee9e-4744-4e3f-9c02-b750fa30154f',
'cftoken': '0',
'RPILOCATOR': '0',
'CFID': '8be7ee9e-4744-4e3f-9c02-b750fa30154f',
'CFTOKEN': '0',
}
headers = {
'accept': 'application/json, text/javascript, */*; q=0.01',
'accept-language': 'en-US,en;q=0.9',
'dnt': '1',
'priority': 'u=1, i',
'referer': 'https://rpilocator.com/?cat=PI5',
'sec-ch-ua': '"Google Chrome";v="131", "Chromium";v="131", "Not_A Brand";v="24"',
'sec-ch-ua-mobile': '?0',
'sec-ch-ua-platform': '"macOS"',
'sec-fetch-dest': 'empty',
'sec-fetch-mode': 'cors',
'sec-fetch-site': 'same-origin',
'user-agent': 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/131.0.0.0 Safari/537.36',
'x-requested-with': 'XMLHttpRequest',
}
params = {
'method': 'getProductTable',
'cat': 'PI5',
'_': '1732192856615',
}
response = requests.get('https://rpilocator.com/data.cfm', params=params, cookies=cookies, headers=headers)While functional, this script includes unnecessary headers and cookies, making it less efficient and harder to customize.
Step 3: Enhancing Python Code for Efficient Web Scraping
I modified the code to make it more concise and flexible. Here’s the final version:
import requests
headers = {
'referer': 'https://rpilocator.com',
'user-agent': 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/112.0.0.0 Safari/537.36',
'x-requested-with': 'XMLHttpRequest',
}
def get_stock_data(country, cat):
params = {
'method': 'getProductTable',
'country': country,
'cat': cat,
'_': '1683866351466',
}
response = requests.get(
'https://rpilocator.com/data.cfm',
params=params,
headers=headers
)
for item in response.json()['data']:
if item['avail'] == 'Yes':
if "pishop" not in item['link']:
stock_info = f"Product available: {item['description']}\nPrice: {item['price']['display']} {item['price']['currency']}\nLink: {item['link']}"
print(stock_info)
if __name__ == '__main__':
cat = 'PI3,PI4,PI5,PIZERO,PIZERO2'
country = 'US'
get_stock_data(country, cat)
Step 4: Explanation of the Final Script
Headers Simplification:
- Removed unnecessary headers like
accept,priority, andsec-*fields to make the request cleaner while ensuring it still works. - Kept
user-agentandx-requested-withto mimic a real browser request.
Dynamic Filtering:
- Added
countryandcatas function parameters to allow filtering stock data by country (e.g.,'US') and product categories (e.g.,'PI4','PI5'). - Used query parameters to request multiple categories at once (e.g.,
'PI3,PI4,PI5').
Data Parsing:
- The API response is in JSON format, and the script iterates through the
response.json()['data']to find products with stock availability (item['avail'] == 'Yes'). - Added a conditional check to exclude specific stores (e.g.,
pishop).
Displaying Results:
- For each available product, the script prints details including the description, price, currency, and link.
How the Filters Were Discovered:
I explored filters by playing around with the query parameters directly in the browser’s network tab. For instance:
catspecifies product categories (e.g.,PI5).countrylimits results to a specific region.
This step-by-step process demonstrates how to start with a basic cURL command, convert it into Python code, and enhance it to create a robust and efficient web scraper tailored to specific needs.
Conclusion
Using a browser’s network tab is an efficient way to uncover API endpoints and scrape data responsibly. It simplifies data retrieval, reduces processing overhead, and makes your scraping workflows more robust. With the example of rpilocator.com, you now have the knowledge to apply this method to other websites and projects.