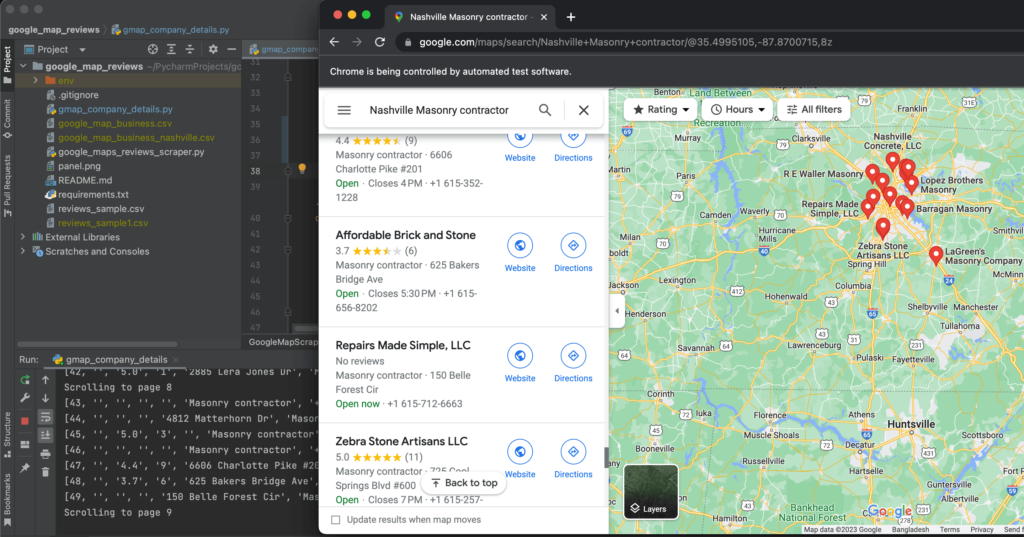
Google Maps has become an essential tool for businesses to showcase their locations, services, and contact information. However, manually collecting these data from Google Maps can be a tedious and time-consuming process. That’s where web scraping comes in handy.
Web scraping is the process of extracting data from websites automatically using software tools. Python and Selenium are two popular technologies for web scraping. In this tutorial, we will walk you through a step-by-step process of using Python and Selenium to scrape business data from Google Maps.
With this tutorial, you’ll learn how to:
- Set up your Python and Selenium environment
- Automate web browser interactions with Selenium
- Use XPaths and CSS selectors to locate elements on a web page
- Extract business data from Google Maps and save it to a CSV file
By the end of this tutorial, you’ll have a powerful tool for collecting business data from Google Maps, which can be used for market research, lead generation, and other business purposes. So, let’s get started!
Installation
Create and activate your python virtual environment and install Selenium and webdriver-manager using,
pip install selenium webdriver-manager
Importing the dependencies
import csv import time from selenium import webdriver from selenium.common import NoSuchElementException from selenium.webdriver.chrome.service import Service from selenium.webdriver.common.by import By from webdriver_manager.chrome import ChromeDriverManager
- csv is a built-in Python module that provides functionality for reading from and writing to CSV files.
- time is another built-in module that provides various time-related functions.
- webdriver_manager is a module that provides an easy way to download and install the ChromeDriver executable.
GoogleMapScraper: the main Class for our project
class GoogleMapScraper:
def __init__(self):
self.output_file_name = "google_map_business_data.csv"
self.headless = False
self.driver = None
self.unique_check = []
- __init__ is a special method that is called when an instance of the GoogleMapScraper class is created. It initializes the instance’s attributes with default values.
- self.output_file_name is a string that represents the name of the CSV file where the scraped data will be saved. By default, it is set to “google_map_business_data.csv”.
- self.headless is a boolean that determines whether the Chrome browser will run in headless mode or not. Headless mode means that the browser will run without a graphical user interface. By default, it is set to False.
- self.driver is a variable that will hold the webdriver.Chrome instance used to interact with the Chrome browser. It is initialized to None because the instance will be created later in the code.
- self.unique_check is a list that will contain the unique identifiers of the businesses that have already been scraped. This is used to avoid scraping duplicate data. It is initialized to an empty list.
Configuring the selenium webdriver
def config_driver(self):
options = webdriver.ChromeOptions()
if self.headless:
options.add_argument("--headless")
s = Service(ChromeDriverManager().install())
driver = webdriver.Chrome(service=s, options=options)
self. Driver = driver
- config_driver is a method that configures the webdriver used to interact with the Chrome browser. It sets the options for the Chrome browser, such as whether it should run in headless mode or not.
- options is an instance of webdriver.ChromeOptions that is used to set the options for the Chrome browser.
- If self.headless is True, then the –headless argument is added to the options object. This tells the Chrome browser to run in headless mode.
- s is an instance of Service that starts the ChromeDriver server. The ChromeDriverManager().install() method is used to download and install the latest version of ChromeDriver.
- driver is an instance of webdriver.Chrome that is created using the service and options objects.
- self.driver is set to the driver instance so that it can be used to interact with the Chrome browser in other methods.
Scrolling down the page to load more data
def load_companies(self, url):
print("Getting business info", url)
self.driver.get(url)
time.sleep(5)
panel_xpath = '//*[@id="QA0Szd"]/div/div/div[1]/div[2]/div/div[1]/div/div/div[2]/div[1]'
scrollable_div = self.driver.find_element(By.XPATH, panel_xpath)
# scrolling
flag = True
i = 0
while flag:
print(f"Scrolling to page {i + 2}")
self.driver.execute_script('arguments[0].scrollTop = arguments[0].scrollHeight', scrollable_div)
time.sleep(2)
if "You've reached the end of the list." in self.driver.page_source:
flag = False
self.get_business_info()
i += 1
The load_companies method is used to load more data. First, the function opens the URL and selects the panel using a pre-defined xpath which we will be using to scroll down the page. The function continues to load data and call get_business_info for each subsequent page until it reaches the end of the page, which is indicated by the appearance of a specific text. At this point, the function sets a flag to stop the while loop and terminates the scraping process.
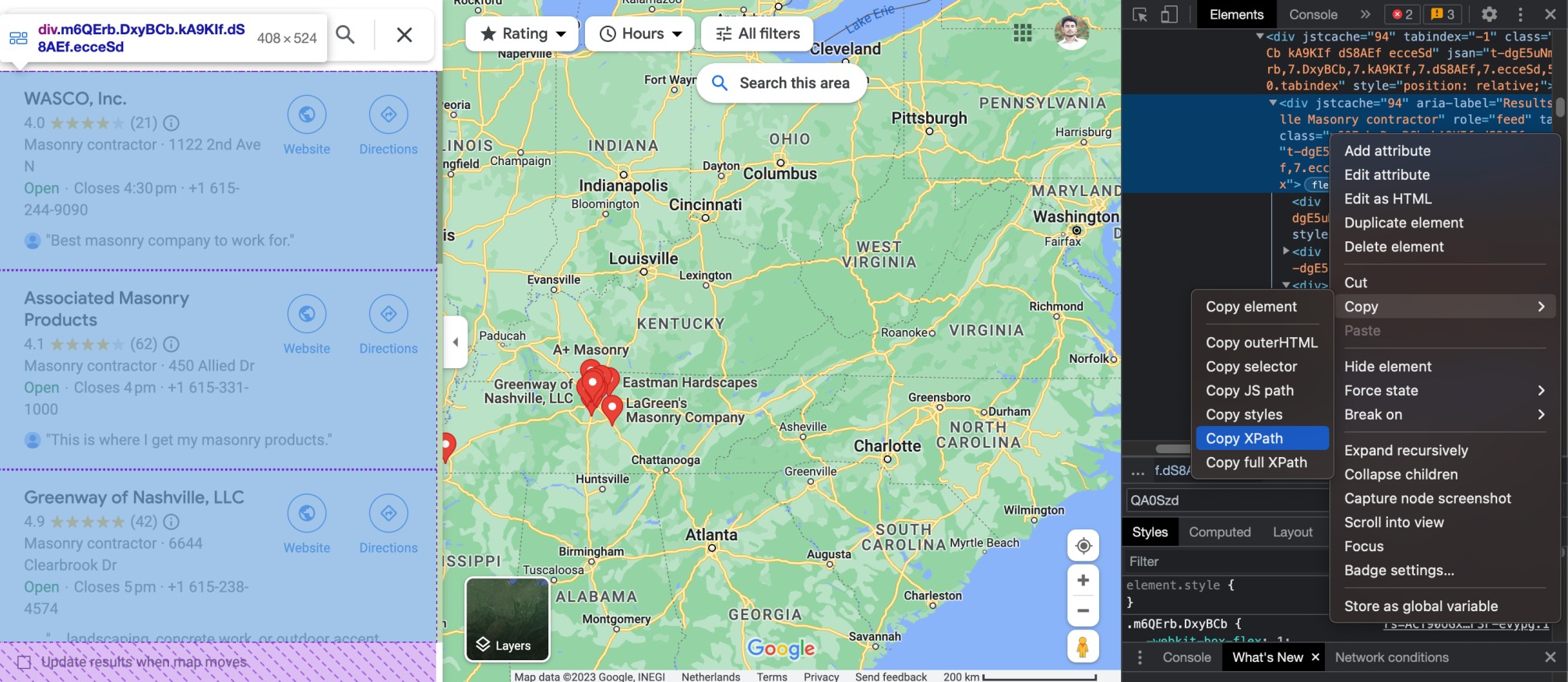
Copy the panel xpath as shown in the image above.
Parsing the Data
def get_business_info(self):
time.sleep(2)
for business in self.driver.find_elements(By.CLASS_NAME, 'THOPZb'):
name = business.find_element(By.CLASS_NAME, 'fontHeadlineSmall').text
rating, reviews_count = self.parse_rating_and_review_count(business)
address, category = self.parse_address_and_category(business)
contact = self.parse_contact(business)
try:
website = business.find_element(By.CLASS_NAME, "lcr4fd").get_attribute("href")
except NoSuchElementException:
website = ""
unique_id = "".join([name, rating, reviews_count, address, category, contact, website])
if unique_id not in self.unique_check:
data = [name, rating, reviews_count, address, category, contact, website]
self.save_data(data)
self.unique_check.append(unique_id)
In this portion of the code, the get_business_info method is defined to extract relevant business information from the Google Maps listing.
For each business, it extracts the name, rating, reviews count, address, category, contact, and website link (if available). It then generates a unique ID using all of these extracted attributes.
First we’ll find out all the loaded business or company items,

self.driver.find_elements(By.CLASS_NAME, 'THOPZb')
It finds all the elements with class name THOPZb on the page. This will return a list of businesses, each of which represents a business. Then we can loop through the items and parse the attributes.
Let’s go through the attributes we are scraping.
Name:

name = business.find_element(By.CLASS_NAME, 'fontHeadlineSmall').text
This extracts the text from the element with class name fontHeadlineSmall.
Rating & Reviews Count:
We made a method to parse rating and reviews count.
def parse_rating_and_review_count(self, business):
try:
reviews_block = business.find_element(By.CLASS_NAME, 'AJB7ye').text.split("(")
rating = reviews_block[0].strip()
reviews_count = reviews_block[1].split(")")[0].strip()
except:
rating = ""
reviews_count = ""
return rating, reviews_count

Within this method we are extracting the element with class name AJB7ye and then splitting them into rating and reviews count. Finally, we are returning them.
Address & Category:
For this portion another method helps us to scrape address and category. Let’s have a look.
def parse_address_and_category(self, business):
try:
address_block = business.find_elements(By.CLASS_NAME, "W4Efsd")[2].text.split("·")
if len(address_block) >= 2:
address = address_block[1].strip()
category = address_block[0].strip()
elif len(address_block) == 1:
address = ""
category = address_block[0]
except:
address = ""
category = ""
return address, category

As you can see there are multiple occurrences of the class name W4Efsd. We will select all of them and take only the third one that contains the category and address.
Contact info:
def parse_contact(self, business):
try:
contact = business.find_elements(By.CLASS_NAME, "W4Efsd")[3].text.split("·")[-1].strip()
except:
contact = ""
if "+1" not in contact:
try:
contact = business.find_elements(By.CLASS_NAME, "W4Efsd")[4].text.split("·")[-1].strip()
except:
contact = ""
return contact

Again we’ll select the elements with the class name W4Efsd. We’ll go for the fourth or fifth item as fourth or fifth element contains the contact information. We’ll find out the correct result applying some additional logics.
Website:
website = business.find_element(By.CLASS_NAME, "lcr4fd").get_attribute("href")

Class name lcr4fd contains the website and above code gets its href attribute of this element to extract the website URL.
Saving the data
Finally we will save the data by calling below method every time we collect a business info,
def save_data(self, data):
header = ['id', 'company_name', 'rating', 'reviews_count', 'address', 'category', 'phone', 'website']
with open(self.output_file_name, 'a', newline='', encoding="utf-8") as csvfile:
writer = csv.writer(csvfile)
if data[0] == 1:
writer.writerow(header)
writer.writerow(data)
What’s next?
If you want to scrape Google Maps using Python and Selenium, just remember: don’t be evil (to Google’s terms of service) and always use your powers for good (or at least for something more productive than just finding the nearest taco truck). Happy scraping! You want the full code?
Here you go,
import csv
import time
from selenium import webdriver
from selenium.common import NoSuchElementException
from selenium.webdriver.chrome.service import Service
from selenium.webdriver.common.by import By
from webdriver_manager.chrome import ChromeDriverManager
class GoogleMapScraper:
def __init__(self):
self.output_file_name = "google_map_business_data.csv"
self.headless = False
self.driver = None
self.unique_check = []
def config_driver(self):
options = webdriver.ChromeOptions()
if self.headless:
options.add_argument("--headless")
s = Service(ChromeDriverManager().install())
driver = webdriver.Chrome(service=s, options=options)
self.driver = driver
def save_data(self, data):
header = ['id', 'company_name', 'rating', 'reviews_count', 'address', 'category', 'phone', 'website']
with open(self.output_file_name, 'a', newline='', encoding="utf-8") as csvfile:
writer = csv.writer(csvfile)
if data[0] == 1:
writer.writerow(header)
writer.writerow(data)
def parse_contact(self, business):
try:
contact = business.find_elements(By.CLASS_NAME, "W4Efsd")[3].text.split("·")[-1].strip()
except:
contact = ""
if "+1" not in contact:
try:
contact = business.find_elements(By.CLASS_NAME, "W4Efsd")[4].text.split("·")[-1].strip()
except:
contact = ""
return contact
def parse_rating_and_review_count(self, business):
try:
reviews_block = business.find_element(By.CLASS_NAME, 'AJB7ye').text.split("(")
rating = reviews_block[0].strip()
reviews_count = reviews_block[1].split(")")[0].strip()
except:
rating = ""
reviews_count = ""
return rating, reviews_count
def parse_address_and_category(self, business):
try:
address_block = business.find_elements(By.CLASS_NAME, "W4Efsd")[2].text.split("·")
if len(address_block) >= 2:
address = address_block[1].strip()
category = address_block[0].strip()
elif len(address_block) == 1:
address = ""
category = address_block[0]
except:
address = ""
category = ""
return address, category
def get_business_info(self):
time.sleep(2)
for business in self.driver.find_elements(By.CLASS_NAME, 'THOPZb'):
name = business.find_element(By.CLASS_NAME, 'fontHeadlineSmall').text
rating, reviews_count = self.parse_rating_and_review_count(business)
address, category = self.parse_address_and_category(business)
contact = self.parse_contact(business)
try:
website = business.find_element(By.CLASS_NAME, "lcr4fd").get_attribute("href")
except NoSuchElementException:
website = ""
unique_id = "".join([name, rating, reviews_count, address, category, contact, website])
if unique_id not in self.unique_check:
data = [name, rating, reviews_count, address, category, contact, website]
self.save_data(data)
self.unique_check.append(unique_id)
def load_companies(self, url):
print("Getting business info", url)
self.driver.get(url)
time.sleep(5)
panel_xpath = '//*[@id="QA0Szd"]/div/div/div[1]/div[2]/div/div[1]/div/div/div[2]/div[1]'
panel_xpath = '//*[@id="QA0Szd"]/div/div/div[1]/div[2]/div/div[1]/div/div/div[2]/div[1]'
scrollable_div = self.driver.find_element(By.XPATH, panel_xpath)
# scrolling
flag = True
i = 0
while flag:
print(f"Scrolling to page {i + 2}")
self.driver.execute_script('arguments[0].scrollTop = arguments[0].scrollHeight', scrollable_div)
time.sleep(2)
if "You've reached the end of the list." in self.driver.page_source:
flag = False
self.get_business_info()
i += 1
urls = [
"https://www.google.com/maps/search/Nashville+Masonry+contractor/@35.5098836,-87.8700415,8z/data=!3m1!4b1"
]
business_scraper = GoogleMapScraper()
business_scraper.config_driver()
for url in urls:
business_scraper.load_companies(url)
Hi,
How did you fix the infinite scrolling problem with google map. I used this but it doesnt work.
last_height = driver.execute_script(“return document.body.scrollHeight”)
while True:
# Scroll down to bottom
driver.execute_script(“window.scrollTo(0, document.body.scrollHeight);”)
# Wait to load page
time.sleep(3)
# Calculate new scroll height and compare it with last scroll height
new_height = driver.execute_script(“return document.body.scrollHeight”)
if new_height == last_height: # if the new and last height are equal, it means that there isn’t any new page to load, so we stop scrolling
break
else:
last_height = new_height
Hi Benjamin,
Thank you for your question! The issue with the code you shared lies in how Google Maps handles infinite scrolling. Unlike simple web pages that rely on window.scrollTo or document.body.scrollHeight for scrolling, Google Maps typically uses a specific scrollable container for lists, such as search results or reviews. These containers are not part of the main window object, so scrolling the main page won’t affect them.
here’s the working code,
panel_xpath = ‘//*[@id=”QA0Szd”]/div/div/div[1]/div[2]/div/div[1]/div/div/div[2]/div[1]’
scrollable_div = self.driver.find_element(By.XPATH, panel_xpath)
flag = True
i = 0
while flag:
print(f”Scrolling to page {i + 2}”)
self.driver.execute_script(‘arguments[0].scrollTop = arguments[0].scrollHeight’, scrollable_div)
time.sleep(2)
if “You’ve reached the end of the list.” in self.driver.page_source:
flag = False
self.get_business_info()
i += 1
Here, scrollable_div is the element containing the scrollable content, which you can locate with Selenium. This method ensures you’re targeting the correct element for scrolling.